
Synthetic data workshop: 5 September 2024
Want to know more about working with synthetic data? Join our free workshop!
01 Aug 2024

Stella Telford
02 Jul 2024
With our recent Synthetic Data Workshops proving popular with researchers, we asked our Data Analyst Stella Telford to walk us through her experience of the training and some of her takeaways.
Written by Stella Telford, Data Analyst at Research Data Scotland
Synthetic data has the potential to open up so many opportunities for research, so when I heard that Research Data Scotland were hosting Synthpop workshops I knew I had to take the chance to learn more.
The workshop, run by Professor Gillian Raab, focuses on creating low fidelity synthetic datasets within synthpop, an R package which allows users to create artificial versions of confidential individual-level data.
Crucially, synthetic data allows accredited researchers to begin work on their project before they are granted access to sensitive data. Researchers can use synthetic data to explore if data is suitable for their project and begin to develop code. This synthetic data is also useful for training purposes, allowing users to experiment with realistic datasets.
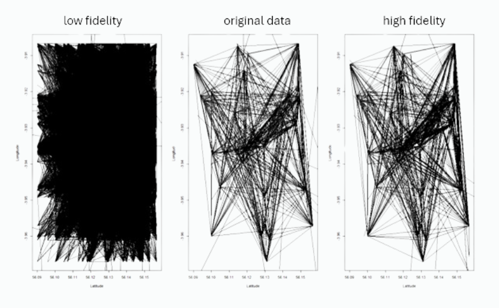
Co-created by Professor Raab, the synthpop package was designed for use by researchers, and allows the relatively straightforward creation of synthetic versions of real data. It can be used to create high and low fidelity datasets — the higher the fidelity, the more closely it resembles the real data it is designed to emulate.
For this workshop, the main aim was to use synthpop to create a low fidelity synthetic dataset. Low fidelity means that the data only resembles real-world data in a very basic way. This type of dataset can be useful for teaching students, or helping programmers to plan code for things like health applications.
“Crucially, synthetic data allows accredited researchers to begin work on their project before they are granted access to sensitive data.”
Attendees were given a dataset to synthesise, which in this case was information collected on bike rentals in Stirling between 2018 and 2023. Professor Raab walked us through the process of generating a low fidelity synthetic version of this dataset, and then we were able to try it for ourselves. We were also shown how to use one of the functions included in the package which allows users to create plots to compare the distributions of your input data with the synthetic version created.
There are different parameters that can be used when synthesising a dataset using synthpop, such as specifying how many synthetic copies of the original dataset you wish to generate. We went over the most important parameters and explained how and why they can be used. This includes parameters for statistical disclosure control (SDC), used to ensure that individuals are not able to be identified from the data. Synthpop allows you to remove replicated uniques (unique combinations in the original data that appear in the synthetic data) from the synthetic dataset you’ve created, as well as add flags to the data to show that it is not real data, among other SDC measures. As well as disclosure control, Synthpop is also a useful tool for checking the quality of synthetic datasets.
While the workshop focused on the creation of low fidelity data, it also touched on creating high fidelity synthetic data with synthpop. Professor Raab showed us some interesting visualisations to illustrate how high fidelity synthetic data can maintain the distributions of variables and the relationships between them.
Professor Raab also went over some of the difficulties you may encounter with certain dataset characteristics and how best to address them, which is really useful if these were to come up in future.
Overall, the workshop is a great introduction to using synthpop. You learn the basics of creating a low fidelity synthetic dataset, which you are then able to apply to your own datasets, as well as more on the statistical disclosure control measures and quality checking within the package. Synthpop is a useful tool that can be used to suit your needs – whether that be making high or low fidelity synthetic data.
Our next Synthetic Data Workshop with Professor Gillian Raab will take place on Thursday 5 September 2024. Find out more.
If you’re interested in attending future workshops or events about Synthetic Data, make sure to sign up to our engagement contact list, and select Synthetic Data as one of your interests, and we’ll be in touch.
Related content
Want to know more about working with synthetic data? Join our free workshop!
01 Aug 2024

Reflecting on how synthetic data can plug the data gap.
Dr Lynne Adair
19 Dec 2022
To stay updated with Research Data Scotland, subscribe to our monthly newsletter and follow us on X (Twitter) and LinkedIn.
